{kind=link}
{kind=link}
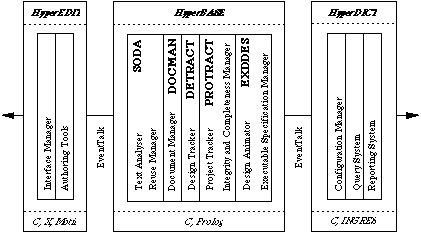
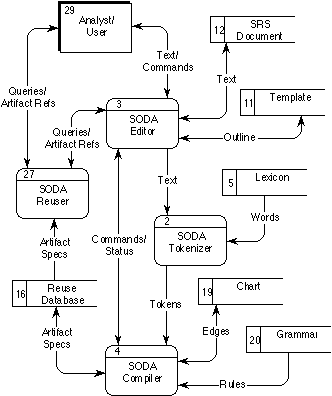
Figure 1 - HyperCASE environment with SODA
This poster paper was presented at ASWEC'93 in Sydney, Australia.
Jacob L. Cybulski and Karl Reed
Amdahl Australian
Intelligent Tools Programme
Department of Computer Science and Computer Engineering
La Trobe University, Bundoora, Vic.
3083, Australia
Phone: +613 479 1270, Fax: +613 470 4915
Email: jacob@latcs1.lat.oz.au, kreed@latcs1.lat.oz.au
This paper describes a method of using document templates and controlled language in the creation and analysis of informal software requirement specifications. The proposed method was prototyped as Software Designer's Aide (SODA), the sub-system of the hypertext-based software engineering environment, HyperCASE.
SODA templates define the requirement document's outline, its layout and the text typeface, thus, enforcing adherence to the selected specification and publishing standards. An even more important feature of the SODA templates, though, is their ability to prescribe a near-natural syntax and semantics of the text contained in them. As a result, SODA templates facilitate semi-automatic compilation of informal software requirements into the attributes, relationships and constraints imposed upon the set of reusable design artefacts. The resulting document representation leads to a stricter form of requirements, thus allowing their use in further, more formal, stages of the software life-cycle. The by-product of the requirement compilation process is a cross-reference between specification and design documents, which can subsequently be used as the basis of inter-document hyper-navigation.
Software Designer's Aide
(SODA) is a tool assisting software designers, first, in the creation and structuring of text-based software requirement specifications (SRS) and other types of non-diagrammatical software documents, and subsequently, in the documents examination with the aim of detecting references to already existing design artefacts, thus, promoting reuse at the earliest stages of the software life-cycle.The philosophy of SRS construction as used in SODA is quite different from that adopted by the commercially available requirement capture systems (Rock-Evans 1989). Majority of CASE environments allows for the creation, refinement and subsequent maintenance of elaborate diagrammatical requirement documents by skilled analysts, but they do not have any means of deriving formal requirements from those originally stated by non-technically oriented clients, nor can the CASE systems transform formal specifications back into the form readily understood by the client. SODA provides the facilities for semi-automatic structuring and analysis of requirement documents expressed in near-natural, controlled English; thus, aiming at closing the gap between the need for informality in the communication with non-technical personnel and the necessity to formalise the requirements before they could be processed automatically in the later phases of the software life-cycle.
SODA's text structuring and analysis capabilities are central to the operation of the software engineering environment, HyperCASE (Cybulski and Reed 1992 - Figure 1), which amongst other CASE tools (Rock-Evans 1989; Rock-Evans and Engelien 1989) is characteristic in its approach to integrating project deliverables via a common knowledge-based repository, hypertext linking of software documents, and navigation between them, concepts not dissimilar to those used in the Neptune project (Bigelow 1988) and Ishys (Garg and Scacchi 1989).
Although SODA's main emphasis is on the analysis of requirement documents, it is also planned for SODA to be employed in :-
It is important that whatever are the methods used in the process of developing a software requirement specification, whether formal or informal, utilising text or diagrams, constructed by the user directly or with the analyst's assistance, the documents produced should conform to the following criteria (Davis 1990, pp 296-299):
On the basis of these criteria, the conventional approaches to the construction of natural language, i.e. informal and unstructured, requirement specifications compare very poorly with the formally rigid description techniques. Although natural language descriptions can be easily understood by non-technical personnel, they lend themselves to modifications and further annotations, at the same time, they can be unacceptably vague and ambiguous, they cannot be readily transformed into formal design concepts, their contents cannot be easily assessed for consistency nor completeness, their free-format contradicts the requirement for document organisation, etc. This inconvenience of natural language specifications drew majority of CASE developers away from informality, nevertheless, non-technical users, and in fact many computer professionals as well, still prefer to state their requirements in plain natural language. They regard natural language not only as the most familiar form of communication, but also as the one in which most of the implicit information can be omitted and the reader's attention could be focused on the explicitly expressed important component of specifications, thus, leading to SRSs that are more concise, less complex and thus cheaper in maintenance than the formal ones (Balzer, Goldman et al. 1978).
In the SODA project we recognised the user and developer's community preference for stating software requirements in English, an intuitive and natural form of expression. However, to counter the disadvantages of informality we focused our efforts on some of the practical constraints (1-10) imposed on SRS tools, i.e. improving the organisation of SRS documents, the formalisation of informal texts and the assessment of documents' consistency and completeness.
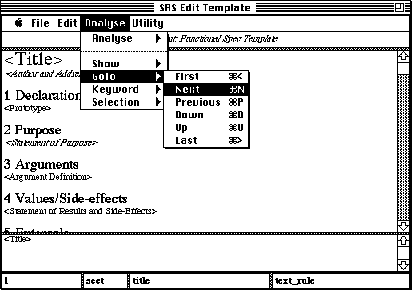
We followed Barstow's suggestions (1984) to convert informal SRS documents into a set of formal structures, which SODA assembles into HyperCASE data dictionary entries, so that the resulting formal document representations can be manipulated by other HyperCASE design tools. The process of document formalisation starts with the imposition of rigid, template-based, organisation of SRS documents, the technique previously utilised in the organisation and maintenance of hypertext documents (Catlin and Garett 1991). SODA templates define the document publishing (layout, fonts, styles, sizes and colours) and specification (outline and contents) standards, but more importantly, the templates also define the grammatical rules that the document sections and paragraphs are forced to follow, to allow their semi-automatic analysis by the SODA compiler (Cf. Figure 2 - note that the lower part of the SODA screen shows the information about the currently selected paragraph or section, i.e. its editable contents, its levelling in the template, the paragraph type, the type style, and the name of the grammatical rule used to compile the current paragraph, all paragraph attributes can be modified via pop-up menus and dialogue boxes).
The SODA compiler is based on the text scanning techniques used previously in a number of successful applications in text classification and automatic concept identification in text, e.g. ATRANS, CBR/Text, or IBS (scanning the banking transactions), VOX (converting sketchy military messages), NL (recording ship movement), Earli (scanning the contents of Yellow Pages), SCISOR (processing the financial news), TIS (Reuter's text classification), TCS (general purpose text classification), or Realist (classifying the patents) (Engelien and Ronnie 1991). The compiler identifies references to certain classes of reusable software components stored in the HyperCASE data dictionary, but it goes well beyond simple pattern matching utilised in KIOSK (Creech, Freeze et al. 1991) or Maarek and Berry's application of lexical affinities to requirement extraction (1989). Similarly to NLH project (Tichy, Adams et al. 1989), SODA truly compiles requirement documents with the use of semantic grammars specified in templates. The compiled data structures are then stored in a relational data dictionary as in the CAPTURE system (Alshawi 1985). Subsequently, SODA uses the acquired information to determine the location of hypertext buttons that allow navigation between textual components of SRS documents, as in the work by Raymond and Tompa on Oxford English Dictionary (1988).
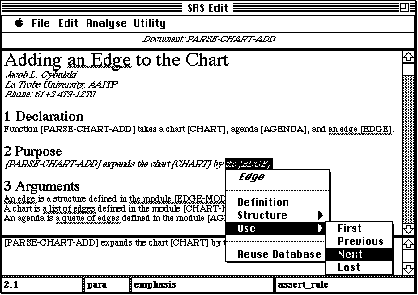
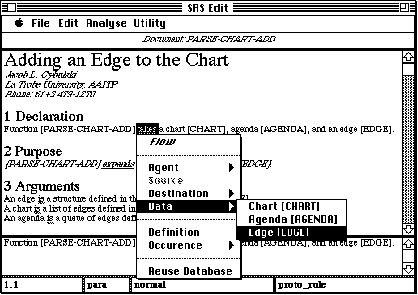
SODA does not aim at full understanding of texts as in SCISOR (Rau and Jacobs 1989), it adheres to the structure of the document templates, rather than, identifying thematically coherent text passages as in the TOPOGRAPHIC system (Hammonwöhner and Thiel 1987), it is also not planned to handle natural language queries similar to those used in intelligent database interfaces (Dahlgren, Ljungberg et al. 1992). SODA, however, does attempt discovering the meaning of newly introduced technical terms from context as in PETRARCA (Velardi, Pazienza et al. 1989). To increase the system performance, we decided to follow Yonezaki's (1989) method of using near-natural, but restricted, rather than natural languages in the requirement analysis, the method used with success in other technical applications (Kincaid, Thomas et al. 1990). Figures 3 and 4 illustrate SODA's ability to recognise and acquire reuse structures from text, in Figure 3 SODA identified relationships between the elements of function declaration (flow mechanism = "takes", agent = "[PARSE-CHART-ADD]", source = "unknown", destination = "[PARSE-CHART-ADD]", and data = "[CHART], [AGENDA], [EDGE]"), in Figure 4 one of these elements was selected for further navigation ("edge [EDGE]").
At the current state of parsing technology, there is no method of automatic analysis of informal text which would guarantee its perfectly accurate interpretation. Thus, we've adopted a "design-and-elaborate" cycle of requirement elucidation (Saeki, Horai et al. 1989). We request HyperCASE users to derive their designs from partially correct interpretations of requirement documents. Throughout the process, we observe all attempts to further elaborate, change, or re-interpret the SRS, in which case we also alter our formal representation of the document. A similar method of allowing the maximum feedback from the user through the interactive interpretation of informal specifications was undertaken in the Requirement Apprentice (Reubenstein and Waters 1989).
SODA consists of a number of clearly identified sub-systems, i.e. SODA requirement and template editor, SODA tokenizer and compiler and finally the SODA reuser (Cf. Figure 5).
Both editors are integrated into a single software package.
SODA's initial prototypes were developed (and are still extended) on Apple Macintosh with Open Prolog (SODA compiler and tokenizer), Hypercard (SODA editor) and Think C (glue). Currently the SODA system is being ported to UNIX distributed over Amdahl/UTS with IF/Prolog (SODA compiler), C with Lex and Yacc (SODA tokenizer), X/OSF Motif (SODA editor) and IBM Risc/AIX with Ingres/SQL database (SODA lexicon and in future also the reuse database). The main emphasis in the current development is put on developing the Motif word-processing widget with hypertext extensions and on improving the SODA compiler to handle more elaborate grammars. SODA's integration with other HyperCASE components is still under consideration.
This paper described SODA, the software requirement specification and analysis tool. The tool allows the construction of document templates and their subsequent use to produce an SRS text. SODA enforces the use of the restricted English, which allows automatic identification of text references to reusable software artefacts. Once the analysis is completed, SODA permits to hyper-navigate between the related concepts. This ability to quickly access and cross-reference the requirement information certainly enhances the software reuse at the earliest stages of the software development.
Throughout this article, SODA was described as the system for automatic analysis of software requirement specification documents, and this was the intended use for the tool, especially when integrated with the HyperCASE environment. However, we also anticipate other uses for SODA, at the very least handling comments attached to diagrammatic specifications, possibility of analysing annotated design decisions, performing domain analysis, or designing specialised design languages (e.g. pseudo-code). There are also, many other non-software-engineering applications of SODA, e.g. SODA could be customised to act as a syntax editor, as a database interface with the capability of data extraction from text documents, as a hypertext tool, etc. All these new applications will be investigated in the future.
The authors wish to acknowledge the direct financial support of Amdahl Australia and of both La Trobe University and Prometheus Software Developments. Assistance has also been received from the Victorian State Government. We would like to thank Mr. Arthur Proestakis and Mr. Robert Van Doorn for their input into the implementation of SODA, and the rest of the AAITP team for their invaluable comments on the range of applications of the tool. The moral support and encouragement of Prof. Tharam S. Dillon are also gratefully acknowledged.
Alshawi, H. (1985). Creating relational databases from English texts. Proc. Second Conference on Artificial Intelligence Applications: The Engineering of Knowledge- Based Systems, Miami Beach, FL.
Balzer, R. M., N. Goldman, et al. (1978). "Informality in Program Specifications." IEEE Trans. on Software Eng. SE-4(2): 94-103.
Barstow, D. (1984). "A perspective on automatic programming." The AI Magazine 5(1): 5-28.
Biebow, B. and S. Szulman (1989). Enrichment of semantic network for requirements expressed in natural language. Information Processing'89, San Francisco, California, North-Holland.
Bigelow, J. (1988). "Hypertext and CASE." IEEE Software : 23-27.
Catlin, K. S. and L. N. Garett (1991). Hypermedia templates: an author's tool. Hypertext'91, San Antonio, Texas, ACM.
Creech, M. L., D. F. Freeze, et al. (1991). Using hypertext in selecting reusable software components. Hypertext'91, San Antonio, Texas, ACM.
Cybulski, J. L. and K. Reed (1992). "A Hypertext-Based Software Engineering Environment,." IEEE Software (March): 62-68.
Dahlgren, H., J. Ljungberg, et al. (1992). Accessing the repository using linguistic knowledge. Next Generation CASE Tools. Amsterdam, IOS Press. 132-143.
Davis, A. M. (1990). Software Requirements: Analysis and Specification. Englewood Cliffs, New Jersey, Prentice Hall.
Engelien, B. and M. Ronnie (1991). Natural Language Markets: Commercial Strategies. London, England, Ovum Ltd.
Garg, P. K. and W. Scacchi (1989). "Ishys: Designing and Intelligent Software Hypertext System." IEEE Expert : 52-63.
Hammonwöhner, R. and U. Thiel (1987). Context oriented relations between text units - a structural model for hypertexts. Hypertext'87, Chapel Hill, North Carolina, ACM.
Kincaid, J. P., M. Thomas, et al. (1990). Controlled English for international technical communication. Human Factors Society 34th Annual Meeting, Orlando, Florida,
Maarek, Y. S. and D. M. Berry (1989). The use of lexical affinities in requirement extraction. 5th International Workshop on Software Specification and Design, IEEE Computer Society Press.
Prieto-Diaz, R. (1991). "Implementing faceted classification for software reuse." CACM 34(5): 88-97.
Rau, L. F. and P. S. Jacobs (1989). "NL ^ IR: Natural language for information retrieval." International Journal of Intelligent Systems 4: 319-343.
Raymond, D. R. and F. W. Tompa (1988). "Hypertext and The Oxford English Dictionary." Communications of the ACM 31(7): 871-879.
Reed, K. and D. C. G. Cleary (1992). On the issue of `completedness' of documents produced during a software project. Dept. of Comp. Sci. and Comp. Eng., La Trobe University.
Reubenstein, H. B. and R. C. Waters (1989). The Requirements Apprentice: An initial scenario. 5th International Workshop on Software Specification and Design, IEEE Computer Society Press.
Rock-Evans, R. (1989). CASE Analyst Workbenches: A Detailed Product Evaluation. London, England, Ovum Ltd.
Rock-Evans, R. and B. Engelien (1989). Analysis Techniques for CASE: A Detailed Evaluation. London, England, Ovum Ltd.
Saeki, M., H. Horai, et al. (1989). Software development process from natural language specifications. 11th International Conference on Software Egineering, Pittsburgh, Pennsylvania, IEEE Computer Press.
Tichy, W. F., R. L. Adams, et al. (1989). NLH/E: A natural language help system. 11th International Conference on Software Engineering, Pittsburgh, Pennsylvania, ACM.
Velardi, P., M. T. Pazienza, et al. (1989). "Acquisition of semantic patterns from a natural corpus of texts." SIGART Newsletter April(108): 115-123.
Yonezaki, N. (1989). Natural language interface for requirement specification. Japanese Perspectives in Software Engineering. Singapore, Addison-Wesley, Pub. Co. 41-76.
[1]
Note that HyperCASE defines "completedness" of documents as their fitness to be further processed by the software project tasks dependant on them.