Dept of Computer Science and Computer Engineering
La Trobe University
Bundoora Vic 3083, Australia
Phone: +613 9479 1270
Fax: +613 9749 3060
Email: jacob@cs.latrobe.edu.au.
Carol M. Jackway
Dept of Information Management and Library Studies
Faculty of Business
Royal Melbourne Institute of Technology
Melbourne Vic 3000, Australia
Email: S9502270@disinformation.bf.rmit.edu.au.
Hypertext, a medium in which text is presented in a non-linear fashion, can provide a flexible and intuitive way of navigating through an information space. Yet this freedom places an extra cognitive load on hypertext readers who can become lost or disoriented. Modern hypertext systems include facilities such as browsers, maps, bookmarks or footprints which aim to alleviate this problem, yet they are limited in effectiveness. We propose an alternative approach to reducing reader disorientation which provides hypertext devices limiting the space of navigational decisions based on reader's goals, interests and abilities. To this end, we utilise an event parser based on recursive transition networks capable of monitoring, predicting and guiding a hypertext dialogue with the user. The prototype system, HyperCAL, illustrates the main features of such a parser, it integrates hypertext, computer-aided learning and knowledge-based techniques, and consists of a Prolog back end and a HyperCard interface. The system was applied to the problem of delivering tutorial material on phrase structure grammars.
Hypertext, Computer-Aided Learning, Knowledge-Based Systems
Traditional texts are organised in a linear fashion. Usually, readers start at the beginning and read left to right, top to bottom, until they reach the end. Hypertext is a medium in which text is presented in a non-linear fashion. The text is organised into chunks or nodes which have a central theme or discuss a certain concept. Nodes are the fundamental units of a hypertext and can range in size from a few words to a whole document. Related nodes are connected by machine-supported links and the reader moves through the document by traversing these links. It is up to the author to determine which nodes should be linked to which others. The on-screen presence of a link is indicated by a symbol, icon, italicised or underlined text, and is called the link source or anchor. The user activates the link anchor by clicking it with the mouse or by using the keyboard, and this has the effect of traversing the link to arrive at the destination node. Therefore, the reader may navigate through the document by following any sequence of links and is not restricted to the physical ordering of the nodes. (Berk & Devlin, 1991a).
Hypertext frees the user from the bounds of the linear document. It builds on the associative ability of the human mind, allocating to the computer the task of storing and presenting information, and to the human the task of choosing the navigation path through it (Nielsen, 1990; Devlin & Berk, 1991). To a degree, it removes the distinction between reader and author, allowing users to annotate, bookmark and modify nodes as they read them. Hypertext puts control into the reader's hands, encourages exploration of the document space, enables browsing by association, encourages integrative thought, and facilitates mental associations in the reader by providing physical associations in the text. Furthermore, hypertext aims to provide a user-friendly interface by incorporating elements which are intuitive and familiar to users, eg. text, graphics, buttons and menus.
Hypertext has been successfully used in applications as diverse as a dictionary (Raymond & Tompa, 1987), a university information system (Nicolson, 1990), a training manual (Akscyn, McCracken & Yoder, 1987), or a software engineering information management system (Garg & Scacchi, 1990; Cybulski & Reed, 1992). Balasubramanian (1994) and Conklin (1987) provide excellent surveys of different hypertext concepts, techniques, methods and systems.
Although hypertext is a very useful and powerful tool, it also has certain drawbacks (Raskin, 1987). One of the usability problems with hypertext is the potential for the user to become 'lost in hyperspace' (Nielsen, 1990; Littleford, 1991). This occurs when readers navigating through a hyperdocument by jumping from one node to another, lose track of where they are in the document, or why they came down a particular path. The more complex the network of hyper-links, the greater the chance of this happening, as the cognitive overhead of the user making navigational decisions given a large number of links to choose from, increases. There are several solutions to this problem.
There is a range of other navigational mechanisms which aim to alleviate the problem of becoming lost in hyperspace. These include (Nielsen, 1990):
We propose another method which could significantly enhance existing navigational mechanisms. The method aims to assist the user during hypertext navigation by reducing a decision space in the process, thus, focusing user attention on a specific topic. Our approach is motivated by the assumption that a reader of a hypertext document has a specific objective to reach, thus, the system should provide such information and in such an order which will lead the user towards this goal. We call this mode of operation a user-centered approach to providing hypertext information. Consider the following examples.
In the past, focusing reader's attention was achieved mainly by information-centered approach to delivering hypertext information, i.e. by structuring it into a neat hierarchy of concepts or threading it with a mesh of hypertext connections. Such an approach to hypertext management has several obvious advantages. All user decisions are predicted and predefined in advance by hypertext designers. The subsequent selection of navigational options is entirely user responsibility. The system does not need to take any initiatives but rather passively responds to the user 'exploring hyperspace' or 'being lost in hyperspace'. As the logic of navigational paths is wired into hypertext information and linking, thus, the system does not need any memory of previous interaction with the user or the user intentions which drive his or her behaviour. In information-centered approach, the hypertext model can be kept simple and minimal and the implementation inexpensive. At the same time the system is rigid and unforgiving.
Summarising, information-centered approach presumes that the required knowledge could be accessed by simple link traversal - which is incorrect in a travel or a shopping system. It disregards the reader's interaction with the system prior to reaching a given set of information nodes, it also denies the user a chance of structuring the search for required information according to his or her needs, knowledge or skills - the preferred option in a shopping example. It assumes that a reader has a good understanding of information domain and will make correct decisions leading to required information - this is clearly not true in a case of a tutoring system. Hence, in all those cases where the complexity of interaction exceeds that of simple link following, no amount of structuring hypertext information will ever help the user in effective navigation. We need to rely on the user-centered approach to information management.
We propose to deal with the problem of user-centered hypertext navigation by means of techniques drawn from the areas of natural language processing (NLP - Gazdar & Mellish 1989), computer-aided learning (CAL - Burns & Capps, 1988), and knowledge-based systems (KBS - Luger & Stubblefield, 1989).
Our method relies on a view of hypertext navigation to be a tutorial dialogue between two intelligent agents, the user being a student and the hypertext system being a tutor. The main objective of the student is to acquire maximum information about a certain topic of discourse, while the tutor aims to convey this information in the best possible way, while taking into consideration the student's learning progress. Both of the participants in this dialogue must be capable of understanding and anticipating the other party's objectives, needs and abilities. Only when such understanding is achieved, the hypertext system may reduce the number of available navigational options to best serve user learning objectives. The proposed model can, thus, be described in the following terms.
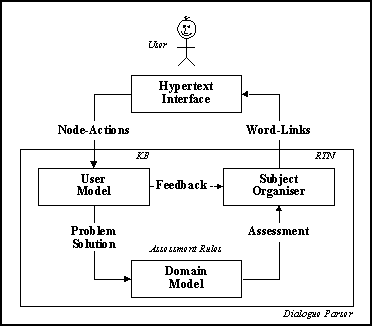
The three elements of the user-centered hypertext management, i.e. the domain and user models plus the subject-organiser, combine into a single module interpreting user input into the system and producing an appropriate feedback to the user. The module is, thus, responsible for parsing the student/tutor hyper-dialogue.
The prototype system embodying our user-centered method of hypertext interaction, HyperCAL, was constructed in PROLOG (hyper-dialogue parser) and HyperCard (hypertext interface), communicating via a protocol consisting of PROLOG queries and HyperCard messages. From the architectural point of view, HyperCAL shares many features with USHIR implementing an information resource system (Nicolson, 1990). Both of the systems rely on the representational strength and inferencing flexibility of a logic language, and, the elegance and ease of use of a graphical user interface system. However, our main example used to illustrate HyperCAL's functionality was based on a tutorial in phrase structure grammars, hence, we had a distinct requirement for extremely flexible interaction between the user and the system, and the particular need for responsiveness to the user skills and abilities. HyperCAL had to use many attributes not present in USHIR, nor in fact in many other hypertext systems, but instead our system borrowed some concepts and techniques from NLP, CAL and KBS.
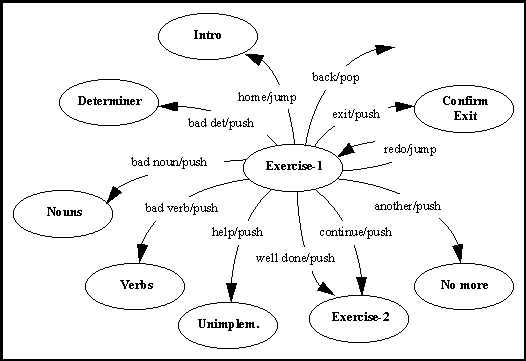
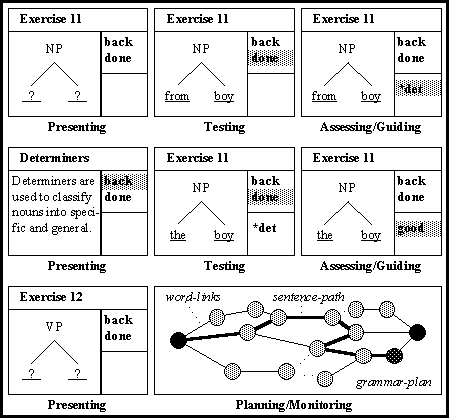
HyperCAL nodes denote either information pages of exercises. All nodes are presented to the user as a window with a menu depicting hypertext links to some standard destinations (e.g. Help, Exit, Home, Back, Done, and Cancel), and to other nodes as determined by the Subject Organiser. The connections between the HyperCAL nodes, are modelled in a form of a hyper-dialogue grammar described with recursive-transition networks (RTNs - cf. figure 3). HyperCAL RTNs have links of four types (jump, push, pop and quit) and encode transitions between pages of information triggered upon receiving of word-link input from the user selecting a menu item. This process of transition from one hypertext node to another is equivalent to the continuous RTN parsing of the user input. An RTN for a single hypertext node (node 8 - "Exercise 1") is encoded in Prolog as follows:
link(jump,'8','home','1'). % "Introduction"
link(push,'8','exit','16'). % "Confirmation"
link(push,'8','help','16.1'). % "Unimplemented"
link(pop,'8','back',_). % previous screen
link(jump,'8','redo','8'). % itself
link(push,'8',another,'16.2'). % "No More"
link(push,'8',continue,'9'). % "Exercise 2"
link(push,'8','well done','9'). % "Exercise 2"
link(push,'8','bad det','2.1.5'). % "Determiners"
link(push,'8','bad noun','2.1.1'). % "Nouns"
link(push,'8','bad verb','2.1.3'). % "Verbs"
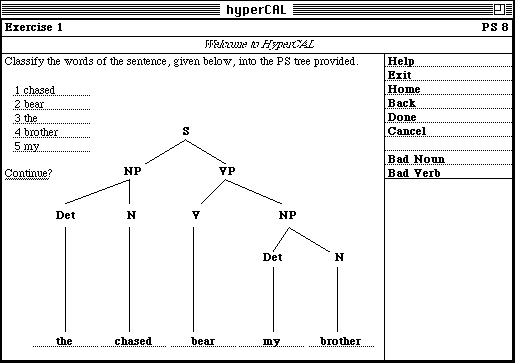
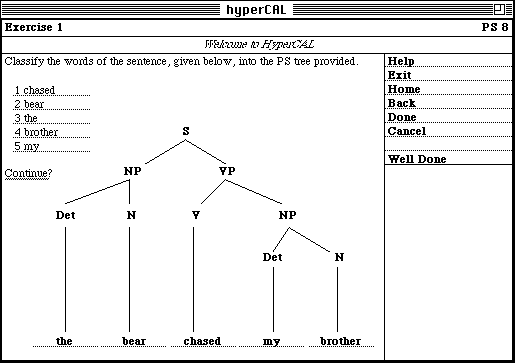
As described in the previous section, all HyperCAL nodes require some degree of processing by the user, e.g. all our exercises prompt the user to fill-in the form of data fields, which represent the elements of a phrase-structure tree (cf. figure 4). Once the user complies with the instructions supplied with the exercise and completes a problem solution (by selecting "Done" from the supplied menu), HyperCAL first stores the solution in the User Model, and then invokes several assessment procedures being part of the HyperCAL Domain Model. HyperCAL feedback on this assessment is passed back to the user in a form of a new menu. The menu will allow the user to navigate to only those destinations which are most relevant to the current state of user knowledge, the problem at hand, the solution provided by the user, and the assessment made by HyperCAL.
For instance, the following (simplified) assessment rules for node 8 ("Exercise 1"), will allow to detect several different types of commonly made mistakes in process of grammatical analysis of the sentence "the bear chased my brother".
assess('8', [the, bear, chased, my, brother], 'well done').
assess('8', [Det1, _, _, Det2, _], 'bad det') :-
not lexicon(8, Det1, det) ; not lexicon(8, Det2, det).
assess('8', [_, N1, _, _, N2], 'bad noun') :-
not lexicon(8, N1, noun) ; not lexicon(8, N2, noun).
assess('8', [_, _, V, _, _], 'bad verb') :-
not lexicon(8, V, verb).
The pattern matching invoked on these assessment rules will match the correct sentence "the bear chased my brother" with response 'well done' (cf. figure 5), while an incorrect order of words "the chased bear my brother" will match two possible responses, i.e. 'bad noun' and 'bad verb' (cf. figure 4). The generated feedback can subsequently be displayed in a form of an extended menu and on selection to be compared with the previously displayed linking information. This will allow to 'push' node '9' ("Exercise 2") on correct answer, or nodes '2.1.1' ("Nouns") and '2.1.3' ("Verbs") when a mistake is made (this permits to get some more information and exercises on the areas of further study).
Our example clearly shows that the user-centered model of hypertext dialogue is capable of focusing user attention on only those elements of information hyperspace which are most relevant to the user needs and expertise. Such a method can be used in the context of a tutoring system to hilight user mistakes and to guide him or her to additional reading material explaining the issues surrounding the error or misconception. It could also be used to fast-track the user through the hyperspace whenever the answers are in agreement with our predictions. It should be noted, though, that our prototype did not make an extensive use of the User Model, which at this point in our experimentation was kept to the minimum, simply recording the user successes and failures at decision points.
HyperCAL was implemented in Open Prolog and HyperCard on a Macintosh Powerbook 170 (Jackway, 1994). Here is a summary of our implementation details.
Knowledge Representation
Presentation
Structure
Navigation
This paper has shown that the user-centered interaction with a hypertext system may indeed reduce a decision space confronting the user at any information node in the hypertext system. Furthermore, our prototype system, HyperCAL, demonstrates how the user model and a domain model could be used to constrain the navigational space in a complex interactive hypertext system, such as a tutoring system.
The HyperCAL system was never meant to be a full implementation of the user-centered hypertext model, but rather to be a concept demonstrator for the ideas and concepts in our research. Thus the system suffered certain conceptual and implementation deficiencies. One of the problems in the current implementation of HyperCAL was the lack of an explicit user model which would adhere more closely to those used in intelligent tutoring systems. Such a model would allow knowledge of the user to be accessed directly in the navigation process and this could result in a more dynamic system. To this end, our current work concentrates on replacing RTN parser with a chart parser, and the use of its chart as a vehicle for modeling user knowledge.
The choice of our particular implementation platform resulted in the prototype's inferior performance. Thus, additional effort should also be made to address this problem. This could proceed in two ways:
It would also be useful to implement a complete system which could include educationally effective teaching material and be tested on real students in their learning environment. This would enable practical results to be obtained, and a clearer idea of the issues involved in modeling the knowledge and abilities of real users to be formulated.
Further information about HyperCAL and its comparison with many other hypertext and CAL systems may be found in the thesis by Jackway (1994).